Применение вейвлет-преобразования для сокращения области значения искусственных нейронных сетей на примере задачи распознавания речи
Аннотация
В данной статье предлагается принцип улучшения скорости обучения и обобщающих способностей нейронной сети за счёт сокращения области значений, принимаемых нейронной сетью. На основе данного метода предложена новая модификация нейронных сетей – нейронные сети с модулем обратной вейвлет-декомпозиции сигнала. На примере задачи распознавания речи произведён анализ предлагаемого метода. Эффективность метода подтверждается результатами имитационного моделирования на ЭВМ.
Ключевые слова: нейронные сети, распознавание речи, вейвлет, вейвлет-преобразование, вейвлет-анализ, задача распознавания звука № гос. регистрации 0420900096\000105.13.18 - Математическое моделирование, численные методы и комплексы программ
Ставропольский государственный университет, г.Ставрополь
В данной статье предлагается принцип улучшения скорости обучения и обобщающих способностей нейронной сети за счёт сокращения области значений, принимаемых нейронной сетью. На основе данного метода предложена новая модификация нейронных сетей – нейронные сети с модулем обратной вейвлет-декомпозиции сигнала. На примере задачи распознавания речи произведён анализ предлагаемого метода. Эффективность метода подтверждается результатами имитационного моделирования на ЭВМ.
ЗАДАЧА РАСПОЗНАВАНИЯ РЕЧИ
Исследования в области распознавания речи ведутся с 50х годов [1]. В этой области достигнуты значительные успехи, но основная проблема современного распознавания речи состоит в том, чтобы достигнуть робастности этого процесса. К сожалению, программ, которые могли бы показать эквивалентное человеческому качество распознавание речи при любых условиях, пока не создано [2]. Незрелость существующих технологий связана, прежде всего, с проблемами распознавания шумной и слитной речи.
Известные методы отличаются различными преимуществами, такими, как хороший учёт временной структуры речевого сигнала (устойчивость к сдвигу), устойчивость к вариативности сигнала, устойчивость к шуму, малое ресурсопотребление, размер рабочего словаря и т.п. Но проблема в том, что для качественного распознавания речи необходимо совмещение этих преимуществ в одном методе распознавания.
В целом, при распознавании речи учитываются следующие основные проблемы:
- Временная природа сигнала.
- Вариативность речи за счёт:
- локальных искажений масштаба,
- взаимовлияния(взаимопроникновения) звуков,
- интонации,
- состояния человека.
- Вариативность речевого сигнала за счёт:
- условий записи (дистанция от записывающего устройства, его особенности и т.п.),
- счёт звукового окружения (шум).
- Распознавание слитной речи.
- Дикторонезависимое распознавание.
Подробнее проблемы распознавания речи можно найти в [3].
Среди этих проблем необходимо выделить проблему высокой вариативности за счёт локальных искажений масштаба. Как показано [4], обработка временных сигналов требует устройств с памятью. Эту проблему [1] называет проблемой временной структуры, а [3] проблемой временных искажений. Она заключается в том, что сравнение речевых образцов одного и того же класса возможно только при условии преобразования шкалы времени одного из них. Иными словами, произносим одни и те же звуки с разной длительностью, и более того, различные части звуков могут иметь различную длительность в рамках одного класса. Этот эффект позволяет говорить о «локальных искажениях масштаба» по оси времени.
Возникает необходимость совмещения достоинств различных методов в одном, что приводит к мысли о применении специализированных нейронных сетей. В самом деле, искусственные нейронные сети(ИНС) – это технология, не ограниченная в перспективах и теоретически в возможностях, самая гибкая и самая интеллектуальная. Но при этом необходимость учитывать специфику речевого сигнала проще всего реализовать через использование априорных данных в структуре нейронной сети, что требует специализации.
В этой работе авторы предлагают специализированную архитектуру – нейронные сети с модулем вейвлет-разложения целевого вектора, или нейронные сети с модулем обратной вейвлет-декомпозиции.
СОКРАЩЕНИЕ ОБЛАСТИ ЗНАЧЕНИЯ ИСКУССТВЕННЫХ НЕЙРОННЫХ СЕТЕЙ
Общепринятая схема нейросетевого распознавания речи подразумевает число выходов, равное числу классов распознавания. Каждый выход выдаёт величину, характеризующую вероятность принадлежности к данному классу, или меру близости данного речевого фрагмента к данному распознаваемому звуку. Для простоты описания мы ограничимся одним классом распознавания. Наши рассуждения без потерь могут быть перенесены и на более общий случай.
Обычно речевой сигнал дробится на мелкие отрезки – фреймы (сегменты), каждый фрейм подвергается предварительной обработке, например, с помощью оконного преобразования Фурье. Это делается с целью сокращения признакового пространства и увеличения разделимости классов. В результате каждый фрейм характеризуется набором коэффициентов, называемых акустическим характеристическим вектором. Обозначим длину фрейма как ![]() , а длину характеристического вектора как
, а длину характеристического вектора как ![]() , а сам акустический характеристический вектор в момент времени
, а сам акустический характеристический вектор в момент времени ![]() как
как ![]() .
.
В этом случае предполагается, что для оценки вероятности принадлежности речевого фрагмента данному классу в момент времени ![]() необходимо рассмотреть речевой сигнал в конечном промежутке
необходимо рассмотреть речевой сигнал в конечном промежутке ![]() , где
, где ![]() - длина фрейма во времени, а
- длина фрейма во времени, а ![]() . Такой отрезок обычно называют окном.
. Такой отрезок обычно называют окном.
Таким образом, мы имеем нейронную сеть, производящую отображение входных параметров x(n0-n), x(n0-n+1), … , x(n0), … , x(n0+n-1), x(n0+n) в выходное значение y(n0).
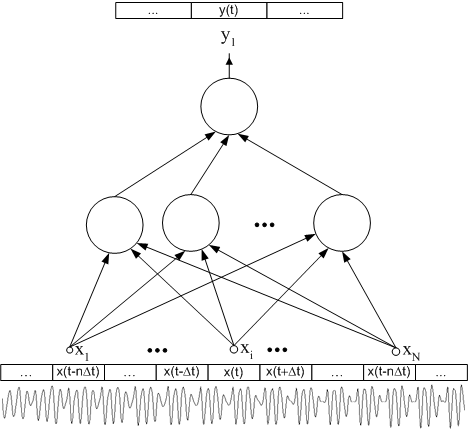
Рисунок 1. Стандартный подход к нейросетевому распознаванию.
Улучшение качества распознавания в стандартном подходе связывается обычно с манипуляциями над входным сигналом, или выбором и улучшением преобразования предобработки.
При этом не учитывается, что выходное значение (см. рисунок 1) является функцией, зависящей от времени, с небольшой скоростью изменения. Для использования свойств выходного сигнала с целью улучшения качества процесса обучения авторами разработан метод сокращения области значений ИНС.
Областью значений нейронной сети будем называть область значения функции, вычисляемой данной ИНС.
Избыточными значеними нейронной сети будем называть подмножество области значений нейронной сети, значения из которого не удовлетворяют условию решаемой ИНС задачи.
Иными словами, аппроксимируемая с помощью ИНС функция может иметь область значения, не совпадающую с областью значений нейронной сети. Это имеет важные последствия. Нейронная сеть ведёт поиск оптимального решения в заданной области значения. Чем меньше эта область, тем меньше вероятность попадания в локальные минимумы, выше точность и скорость обучения.
Поэтому в таких случаях целесообразно аппроксимировать не ту функцию, которая наиболее очевидно следует из условия задачи, а некоторое её представление, область значений которой или совпадает с областью значений нейронной сети, или имеет небольшое множество избыточных значений.
Сокращением области значения ИНС будем называть преобразование g(f(x)) аппроксимируемой функции f(x), при котором её область значения E(f) взаимно-однозначно отображается на множество значений E аппроксимирующей нейронной сети, при этом
![]() (2.1)
(2.1)
и
![]() . (2.2)
. (2.2)
где I – множество избыточных значений ИНС.
Методом сокращения области значения ИНС может служить «вынесение» избыточных значений за область значений ИНС.
Вынесением избыточных значений нейронной сети за область её значения, или исключением избыточных значений будем называть взаимно-однозначное преобразование h(f(x)) аппроксимируемой функции f(x), при котором множество избыточных значений частично или полностью оказывается за пределами области значений ИНС:
![]() . (2.3)
. (2.3)
Примером исключения избыточных значений ИНС может служить масштабирование, или умножение на коэффициент.
Стандартная нейронная сеть имеет ограниченный выход, т.е. каждый компонент выходного вектора находится в рамках некоторого диапазона, как правило, либо (-1;1), либо (0;1) [5]. Для простоты будем полагать, что этот диапазон (0;1). Это означает, что область значений рассматриваемой ИНС - это единичный гиперкуб. Если известно, что значение некоторого выхода нейронной сети по условию задачи не превосходит некоторой величины ![]() , то целесообразно умножить соответствующие ему компоненты целевых векторов на коэффициент k. Таким образом, мы сокращаем избыточные значения
, то целесообразно умножить соответствующие ему компоненты целевых векторов на коэффициент k. Таким образом, мы сокращаем избыточные значения ![]() Более общим случаем масштабирования является линейное преобразование – масштабирование компонентов целевого вектора со сдвигом.
Более общим случаем масштабирования является линейное преобразование – масштабирование компонентов целевого вектора со сдвигом.
Мы видим, что на работу нейронной сети оказывает существенное влияние представление выходных данных в обучающем наборе нейронной сети. Это представление должно уменьшать избыточность описания целевой функции, что влечёт за собой сокращение области значения. Поэтому подбор этого представления является важной задачей проектирования нейронной сети. На представление целевых векторов оказывает влияние три фактора: это выбранная целевая функция, подбор представления, редуцирующего избыточность описания целевой функции, и метод сокращения области значения.
Поэтому нами предлагается следующий алгоритм реализации метода сокращения области значения:
Анализ задачи;
Выбор целевой функции;
Анализ свойств целевой функции;
Подбор представления с низкой степенью избыточности описания;
Подбор архитектуры нейронной сети под выбранное представление;
Подбор метода сокращения области значения.
Следует отметить, что для задачи распознавания речи можно добиться уменьшения области значений от тысячи до трёхсот тысяч раз.
ИСПОЛЬЗОВАНИЕ МЕТОДА СОКРАЩЕНИЯ ОБЛАСТИ ЗНАЧЕНИЯ ИСКУССТВЕННОЙ НЕЙРОННОЙ СЕТИ ДЛЯ ЗАДАЧИ РАСПОЗНАВАНИЯ РЕЧИ
Для применение метода сокращения области значения искусственной нейронной сети для задачи фонемного распознавания нам необходимо выбрать целевую функцию и проанализировать её свойства.
Одна из проблем распознавания речи состоит в том, что в речи нельзя выделить изолированный звук. Форма звука очень зависит от звукового окружения, от того звука, который идёт после него, и того звука, который идёт до него.
Известно, что форма сигнала представляет собой плавный переход одного звука в другой. Проведение чётких границ между звуками некорректно. Правильнее говорить о взаимопроникновении звуков и о зонах фонемных стыков(рис. 2).
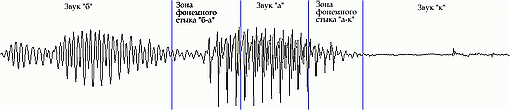
Рисунок 2. Пример взаимовлияния звуков – запись слова «бак».
В качестве модели фонемы в речи предлагается модель «зона фонемного стыка1 – близкий к чистому звук – зона фонемного стыка2».
В качестве целевой функции предлагается мера подобия чистому звуку, произвольно взятая или выделенная в процессе предварительной обработки речи. Введём меру подобия P(t,Ω) данного речевого сигнала в момент времени t чистому звуку Ω. Под чистым звуком понимается звук, произнесённый отдельно, без последующих и предыдущих фонем.
Свойства функций P(t,Ω):
P(t,Ω)=0 или P(t,Ω)<e0 если данный звуковой сигнал не является звуком Ω, или не является речью вообще, где e0 пороговая величина, близкая к нулю;
P(t,Ω)=1 если данный звуковой сигнал является чистым звуком;
P(t,Ω)Î(0,1) в зоне фонемного стыка, причём P плавно возрастает в зоне фонемного стыка ДО звука, и плавно убывает в зоне фонемного стыка после.
Пример функции подобия можно увидеть на рис.3.
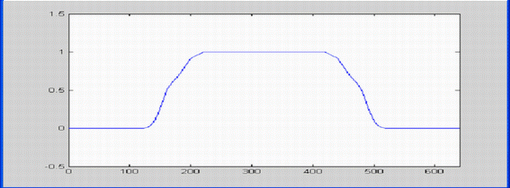
Рисунок 3. Пример функции подобия.
Поясним условие «плавного перехода.
Пусть t1,t2,…,tk,… - отсчёты времени, ti+1=ti+∆t для любого i ∈ N. Тогда
![]() . (3.1)
. (3.1)
Так как функция ![]() , то
, то ![]() и 3.1 можно переписать как
и 3.1 можно переписать как
![]() . (3.2)
. (3.2)
Формулы 3.1 и 3.2 позволяют говорить об априорной информации о целевой фукции.
Как видим, в случае задачи фонемного распознавания можно подобрать целевую функцию таким образом, чтобы имелась априорная информация о выходном сигнале.
Но, как мы видим, данная информация выявляется только во времени. Для её использования в методе сокращения области значения нейронной сети мы должны построить архитектуру нейронной сети таким образом, чтобы она учитывала временной характер временного сигнала. Для этого предлагается перейти к векторному выходу.
Расширим стандартную конфигурацию нейронной сети (описанную в предыдущем разделе) таким образом, чтобы нейронная сеть искала одномоментно вектор значений длиною M - y(n0), y(n0+1), … , y(n0+M), в моменты времени ![]() ,
, ![]() … ,
… , ![]() . Соответственно и число входных векторов нужно увеличить на M - x(n0-n), x(n0-n+1), … , x(n0), … , x(n0+n-1), x(n0+n), … , x(n0+n+M-1), x(n0+n+M).
. Соответственно и число входных векторов нужно увеличить на M - x(n0-n), x(n0-n+1), … , x(n0), … , x(n0+n-1), x(n0+n), … , x(n0+n+M-1), x(n0+n+M).
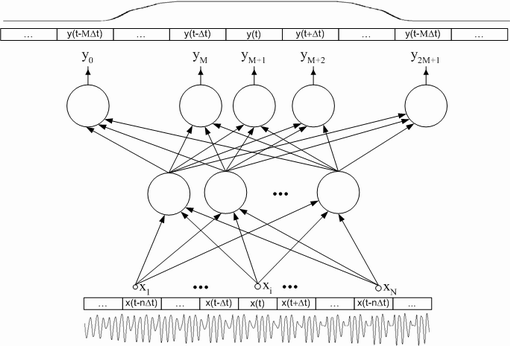
Рисунок 4. Предлагаемая конфигурация нейронной сети для задачи фонемного распознавания.
При такой конфигурации нейронной сети становится возможным произвести преобразование целевых векторов таким образом, чтобы учитывать априорную информацию о целевой функции.
В соответствии с методом сокращения области значения подберём преобразование, устраняющее избыточность описания выходного сигнала.
Так как в нашем случае известно, что ![]() , i=1,2,3,…, имеет смысл заменить значения
, i=1,2,3,…, имеет смысл заменить значения ![]() на
на ![]() , причём
, причём ![]() , и
, и
![]() . (3.3)
. (3.3)
Обратное преобразование легко произвести по формулам
![]()
![]() (3.4)
(3.4)
В этом случае ![]() избыточно. Пусть
избыточно. Пусть
![]() (3.5)
(3.5)
согласно формуле 3.2 ![]() . Таким образом, значения в промежутке
. Таким образом, значения в промежутке ![]() избыточны
избыточны
В такой форме избыточные значения могут быть вынесены за область значения простым умножением на константу, то есть масштабированием выходов.
Пусть
![]() (3.6)
(3.6)
Тогда мы можем промасштабировать каждый второй выход с коэффициентом ![]() .
.
Сравним два варианта построения нейронных сетей. Первый – с немасштабированными выходами ![]() , второй – с масштабированными выходами
, второй – с масштабированными выходами ![]() . Во-первых, в случае ИНС с немасштабированными входами, область значений, рассматриваемая нейронной сетью шире, и для того, чтобы добиться той же точности, что и в случае масштабированных входов, требуется пройти несколько итераций, пока не не будет достигнута точность
. Во-первых, в случае ИНС с немасштабированными входами, область значений, рассматриваемая нейронной сетью шире, и для того, чтобы добиться той же точности, что и в случае масштабированных входов, требуется пройти несколько итераций, пока не не будет достигнута точность ![]() .
.
При этом результирующая точность будет в первом случае меньше. Покажем это.
Пусть ![]() - погрешность выходов нейронной сети на данной итерации. В этом случае погрешность(сумма квадратов) первой нейронной сети будет
- погрешность выходов нейронной сети на данной итерации. В этом случае погрешность(сумма квадратов) первой нейронной сети будет
![]() , (3.7)
, (3.7)
а второй –
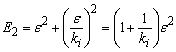 . (3.8)
. (3.8)
ОБОБЩЕНИЕ НА СЛУЧАЙ ВЕЙВЛЕТ-ПРЕОБРАЗОВАНИЯ
Изложим вышесказанное в терминах вейвлет-преобразования.
Преобразование 3.3 является одноуровневым вейвлет-преобразованием Хаара[6-8]. Так же это вейвлет-преобразование известно как одноточечное вейвлет-преобразование Добечи[6,7]. Преобразование 3.4 является обратным к нему.
В общем виде одноуровневое вейвлет-преобразование может быть представлено в виде свёртки, следующей формулой[6]:
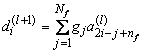 ,
,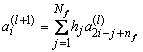 ; (4.1)
; (4.1)
соответствующее обратное преобразование
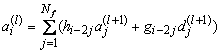 , (4.2)
, (4.2)
где ![]() - число коэффициентов свёртки,
- число коэффициентов свёртки,![]() –
– ![]() (знак
(знак ![]() означает округление до меньшего),
означает округление до меньшего),
g – коэффициенты детализирующего фильтра,
h – коэффициенты «огрубляющего» фильтра,![]() – i-й детализирующий коэффициент на уровне l,
– i-й детализирующий коэффициент на уровне l,![]() – i-й коэффициент «грубой» версии сигнала на уровне l,
– i-й коэффициент «грубой» версии сигнала на уровне l,![]() – исходный сигнал.
– исходный сигнал.
При Nf=2, h={0,5;0,5}, g={-0,5;0.5} мы получаем преобразование Хаара; если при этом ограничится одним уровнем преобразования, мы приходим к формулам 3.3 и 3.4.
Таким образом, мы видим, что предложенное преобразование может быть выражено в терминах вейвлет анализа, и является частным случаем дискретного вейвлет-преобразования. Из этого следует возможность обобщения на случай произвольного вейвлет-преобразования.
Использование вейвлет-преобразования целевых значений (или обратное вейвлет-преобразование выходных значений) оправдано в тех случаях, когда получающиеся в результате величины малы по абсолютному значению. Тогда избыточные значения нейронной сети можно вывести за область значения за счёт масштабирования входов. Возрастание сложности применяемого вейвлет-преобразования оправдано в случае более сложного поведения функции во времени.
Итак, метод сокращения области значения ИНС для задачи распознавания речи можно реализовать с помощью вейвлет-декомпозиции, что позволяет говорить о нейронной сети с модулем вейвлет-преобразования целевых значений.
СХОДИМОСТЬ МЕТОДА. ИССЛЕДОВАНИЕ ВЛИЯНИЯ МАСШТАБИРОВАНИЯ НА ГРАДИЕНТ
Рассмотрим влияние масштабирования целевых значений на градиент.
Масштабированием выхода нейронной сети будем называть умножение на заданный коэффициент соответствующего этому выходу целевого значения.
Под масштабированием целевых значений будем понимать масштабирование нескольких выходов нейронной сети.
Введём следующие обозначения:
E – ошибка слоя. ![]() - l-й компонент;
- l-й компонент;![]() - целевая энергетическая функция;
- целевая энергетическая функция;
dj – желаемый выходной сигнал j-го нейрона слоя;
yj – выходное значение, в общем случае yÎ(0,1);
xi – входное значение;
wij – вес, связывающий i-й вход с j-м выходом;![]() - взвешенная сумма i-го нейрона, t-го слоя,
- взвешенная сумма i-го нейрона, t-го слоя, ![]() .
.
Согласно метода распространения ошибки[5,9-11], имеют место следующие формулы:
![]() (5.1)
(5.1)![]() ,
,![]() . (5.2)
. (5.2)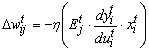 (5.3)
(5.3)
Где ![]() - скорость обучения.
- скорость обучения.
![]() (5.4)
(5.4)
Пусть D(x) – функция, которая позволяет найти производную активационной функции f по её значению
Т.е. если ![]()
То ![]()
![]()
![]() (5.5)
(5.5)
такими функциями, будут, например
![]() (5.6)
(5.6)
для униполярной функции[5] и
![]() (5.7)
(5.7)
для биполярной функции[5]
Рассмотрим для простоты случай униполярной функции.
![]() (5.8)
(5.8)
Проанализируем влияние масштабирования на компонент градиента 5.8.
Пусть выход yj во всех ситуациях не превосходит ![]() . Иными словами,
. Иными словами,
![]() (5.9)
(5.9)
Тогда, с учётом того, что нейронная сеть с униполярной функцией активации выходного слоя выдаёт значения в области (0,1) мы можем промасштабировать выход, увеличив его в k раз. Для этого достаточно промасштабировать соответствующий целевой вектор. Тогда, для масштабированного выхода получаем
![]() (5.10)
(5.10)
Используя (5.6) выводим
![]() (5.11)
(5.11)![]()
![]() (5.12)
(5.12)
Собственно, анализ выражения 5.12 сводится к анализу множителя ![]() . Этот множитель отображает участок униполярной(логистической) сигмоиды на отрезке
. Этот множитель отображает участок униполярной(логистической) сигмоиды на отрезке ![]() в полноценную сигмоиду на отрезке
в полноценную сигмоиду на отрезке ![]() .
.
Мы замечаем, что
![]() (5.13)
(5.13)
монотонно убывающая функция, с учётом 5.9 принимающая минимальное значение при ![]() . Максимум этой функции
. Максимум этой функции ![]() , минимум
, минимум ![]() . При больших k функция близка к линейной.
. При больших k функция близка к линейной.
Пусть ![]() такое значение y, при котором
такое значение y, при котором
![]() (5.14)
(5.14)
Тогда для всех значений ![]() будет верно
будет верно ![]() (5.14). Найдём
(5.14). Найдём ![]() .
.
(5.14) ![]()
![]()
![]()
![]() (5.15)
(5.15)
Оценим соотношение длин отрезков ![]() и
и ![]() .
.
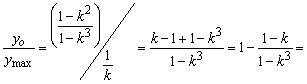
![]()
![]() (5.16)
(5.16)
Т.е. длина отрезка ![]() не более чем
не более чем ![]() часть от длины отрезка
часть от длины отрезка ![]() . Согласно условиям задачи,
. Согласно условиям задачи,
![]()
![]()
![]() (5.17)
(5.17)
Таким образом, при возрастании k мы имеем возрастание градиента для всё большей части значений y, что увеличивает скорость сходимости и улучшает качество процесса обучения.
Пример. При k=5, градиент в случае масштабированного выхода превосходит градиент в случае немасштабированного выхода на ![]() области значения, то есть практически на всей области допустимых значений. Практические эксперименты показали, что для задач распознавания речи величина k=5 реалистична.
области значения, то есть практически на всей области допустимых значений. Практические эксперименты показали, что для задач распознавания речи величина k=5 реалистична.
Итак, использование ИНС с модулем вейвлет-преобразования целевых значений в целом улучшает сходимость нейронной сети по сравнению со стандартной.
РЕАЛИЗАЦИЯ МОДУЛЯ ВЕЙВЛЕТ-ПРЕОБРАЗОВАНИЯ ЦЕЛЕВЫХ ЗНАЧЕНИЙ В НЕЙРОННОМ БАЗИСЕ
Покажем, что нейронную сеть с модулем преобразования целевых значений возможно реализовать целиком в нейронном базисе, как единую нейронную сеть.
Как уже говорилось выше, вейвлет-преобразование целевых значений можно заменить обратной вейвлет-декомпозицией значений нейронной сети. Поэтому к предлагаемой схеме одинаково применимы названия «нейронная сеть с вейвлет-декомпозицией целевых значений» и «нейронная сеть с модулем обратной вейвлет-декомпозиции». Математически между обоими решениями нет никакой разницы, различия могут проявится только на этапе аппаратной реализации.
Важным свойством нейронной сети с модулем обратной вейвлет-декомпозиции является возможность представить его в виде одного или нескольких слоёв нейронной сети, и поэтому такая интерпретация более предпочтительна. Покажем, как это можно сделать на практике.
В тоже время обратное вейвлет-преобразование можно представить с коннекционистких позиций, как слой нейронной сети. В самом деле, одноуровневая обратная вейвлет-декомпозиция может быть представлена как
Согласно [6] одноуровневое обратное вейвлет-преобразование может быть представлено в виде
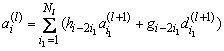 , (6.1)
, (6.1)
где ![]() - «грубая» версия сигнала на l+1 уровне разложения,
- «грубая» версия сигнала на l+1 уровне разложения,![]() - «грубая» версия сигнала на l уровне разложения,
- «грубая» версия сигнала на l уровне разложения,
причём ![]() - i-й выход нейронной сети;
- i-й выход нейронной сети;![]() - число детализирующих и «грубых»(усредняющих) коэффициентов вейвлет-преобразования на уровне l,
- число детализирующих и «грубых»(усредняющих) коэффициентов вейвлет-преобразования на уровне l,![]() - детализирующие коэффициенты l+1 уровня разложения,
- детализирующие коэффициенты l+1 уровня разложения,
а ![]() и
и ![]() - коэффициенты, задающие преобразование.
- коэффициенты, задающие преобразование.
При этом исходный сигнал может быть представлен последовательным применением формулы 6.1.
Введём обозначения
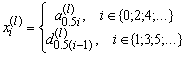 , (6.2)
, (6.2)
и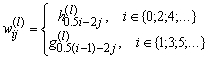 . (6.3)
. (6.3)
Тогда формулу 6.1 можно будет переписать в форме
![]() , (6.4)
, (6.4)
что формально соответствует формуле искусственного нейрона с линейной функцией активации[5].
Таким образом, один уровень обратного вейвлет-преобразования может быть представлен в виде одного слоя нейронной сети. Пример такого слоя представлен на рисунке 5.
Здесь мы видим одноуровневое обратное преобразование Хаара как слой нейронной сети. Здесь круги со знаком «+» означают функцию суммирования, со знаком «-» - вычитания. Иными словами, представленный на рисунке 5 слой нейронной сети реализует преобразование 3.4.
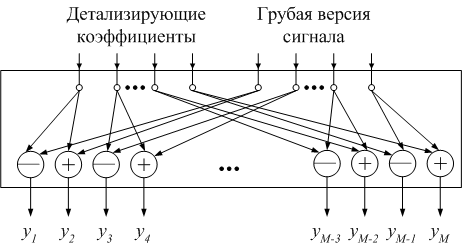
Рисунок 5. Модуль одноуровневого обратного вейвлет-преобразования как слой нейронной сети.
Общая структура перцептронной ИНС с модулем обратной вейвлет-декомпозиции с произвольным числом уровней представлена на рисунке 6. Как видно, начальные слои этой нейронной сети представляют собой многослойный перцептрон, а последующие – обратное вейвлет-преобразование(в данном случае – Хаара) на основе нейронов с линейной функцией активации.
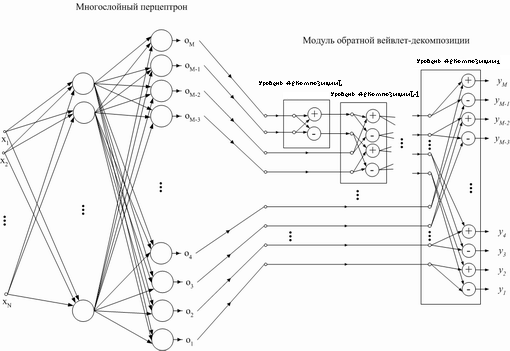
Рисунок 6. ИНС из двухслойного перцептрона с модулем обратной вейвлет-декомпозиции Хаара.
РЕЗУЛЬТАТЫ ПРАКТИЧЕСКИХ ЭКСПЕРИМЕНТОВ
Тестирование и экспериментальная проверка нейронной сети с модулем обратной вейвлет-декомпозиции проводилась на задаче распознавания изолированного звука.
Для экспериментов был выбран речевой корпус из 37 слов. Проверка нейронной сети с модулем обратного вейвлет-разложения проводилась на задаче распознавания изолированного звука «а». Задача усложнялась тем, что длина звука в базе варьировалась в пределах четырёхкратной от минимальной.
Целью эксперимента являлось сравнение двух абсолютно одинаковых нейронных сетей, с идентичной архитектурой, обучаемых одним и тем же алгоритмом, одна из которых обучалась с модулем вейвлет-разложения цели, а другая без него.
Оценка нейронных сети проводилась следующим образом. Было проведено несколько запусков системы (здесь приводятся результаты для 20 запусков). В каждом запуске был выбран контрольный пример с худшим результатом и вычислено математическое ожидание ошибки по всем примерам контрольной выборки. По результатам двадцати запусков был выбран лучший результат по обоим критериям.
В ходе описанных экспериментов были получены следующие результаты (См. табл.1):
Таблица 1. Результаты экспериментов.
Метод |
Критерий №1,% |
Критерий №2,% |
Число эпох |
Дисперсия |
|
Перцептрон |
11,57 |
17,83 |
3873 |
0,03028 |
|
Перцептрон |
0,00330 |
0,00744 |
385 |
0,00016 |
Здесь «критерий №1» - это лучшее математическое ожидание ошибки на контрольной выборке по результатам обучения 20 нейронных сетей.
Соответственно «критерий №2» - это лучшее математическое ожидание супремума ошибки на контрольной выборке по результатам обучения 20 нейронных сетей.
По результатам экспериментов мы можем говорить о весьма примечательных результатах. При этом, как можно видеть по дисперсии, этот результат весьма устойчив.
Можно отметить резкое ускорение сходимости и качественное возрастание обобщающих способностей.
ВЫВОДЫ
В данной статье мы рассмотрели возможности использования априорной информации, заложенной в выходном сигнале за счёт сокращения области значений аппроксимируемой нейронной сетью функции путём линейного преобразования целевых значений на примерах задач распознавания речи. Нами было показано, каким образом масштабирование выходного значения влияет на градиент (и, следовательно, скорость сходимости). Так же было обосновано применение простейших видов вейвлет-преобразования для сокращения области значения нейронной сети в задаче распознавания речи. Было показано, как вейвлет-преобразование целевых значений может быть представлено с коннекционистких позиций – в виде модуля обратного вейвлет-преобразования, реализованного в виде нейронной сети с линейными функциями активации.
В ходе имитационного моделирования на ЭВМ нами было получено экспериментальное подтверждение эффективности предлагаемого метода. Результатом использования модуля обратной вейвлет-декомпозиции является многократное ускорение сходимости (в приведённом случае – на порядок), и многократное уменьшение относительной ошибки на контрольной выборке – до трёх порядков.
Так же следует отметить, что уменьшение области значений понижает вероятность попадания ИНС при обучения в локальный минимум.
Итак, можно говорить о следующих преимуществах вейвлет-преобразования целевых значений:
- ускорение сходимости за счёт преобразования градиента.
- улучшение результирующей точности.
- уменьшение числа итераций за счёт лучшей начальной локализации решения.
- уменьшение вероятности попадания в локальный минимимум.
ЛИТЕРАТУРА
1. Tebelskis, J. Speech Recognition using Neural Networks: PhD thesis … Doctor of Philosophy in Computer Science/ Joe Tebelskis; School of Computer Science, Carnegie Mellon University.– Pittsburgh, Pennsylvania, 1995.– 179 c.
2. Jain, L.C., Martin, N.M. Fusion of Neural Networks, Fuzzy Systems and Genetic Algorithms: Industrial Applications/ Lakhmi C. Jain, N.M. Martin.– CRC Press, CRC Press LLC, 1998.– 297c.
3. Handbook of neural network signal processing/ Edited by Yu Hen Hu, Jenq-Neng Hwang.– Boca Raton; London; New York, Washington D.C.: CRC press, 2001.– 384c.
4. Principe, J.C. Artificial Neural Networks/ Jose C. Principe// The Electrical Engineering Handbook/Ed. Richard C. Dorf.– Boca Raton: CRC Press LLC, 2000.– 2719c.
5. C. Хайкин. Нейронные сети: полный курс, 2-е изд., испр.: Пер. с англ./ Саймон Хайкин.– М.: ООО «И.Д. Вильямс», 2006. – 1104 с.: ил. – Парал. тит. англ.
6. Добеши И. Десять лекций по вейвлетам.– Ижевск: НИЦ «Регулярная и хаотическая динамика», 2001.– 464 с.
7. Ф.Г. Бойков Применение вейвлет-анализа в задачах автоматического распознавания речи: Дис. … кандидата физико-математических наук: 05.13.18/ Фёдор Геннадьевич Бойков.– М, 2003.– 111 с.
8. Haar, A. Zur Theorie der Orthogonalen Funktionen-Systeme/ A. Haar// Math. Ann.– 1910.– No. 69.– c. 331-371.
9. Rumelhart D. E., Hinton G. E., Williams R. J. Learning representations by back-propagating errors / Rumelhart D. E., Hinton G. E., Williams R. J. // Nature (London).– 1986.– N 323.– c. 533-536.
10. Werbos, P. Beyond Regression: New Tools for Prediction and Analysis in the Behavioral Sciences: Phd Thesis/ Werbos P.; Dept. of Applied Mathematics, Harvard University.– Cambridge, Mass., 1974.
11. Werbos, P. J. Backpropagation and neural control: A review and prospectus./Werbos P. J. // IEEE international conference on neural networks.– 1989.– Vol. 1.– c.209-216.